Visit the Zoo!
Learn about ML Algorithms!
Tame an Algorithm!
Behind the Scenes (XML)
Main Site
Contact Me
About Machine Learning Algorithms
Machine Learning is a vaguely defined field that combines concepts from Computer Science, Statistics and Electrical Learning. It is concerned with algorithms that can learn from data and issue predictions based on what that data taught them.
An algorithm is a finite set of instructions that takes in an input, applies those instructions, and outputs a result. The input can be practically anything that can be represented numerically. A block of text can be converted into numbers. So can a picture. Even things in the real world can be approximated numerically. Algorithms can take input of any size -- there are even algorithms that perform operations on infinite numbers! The worry, however, for applying algorithms in day-to-day life is that because they are done through a mechanical, step-by-step process, the size of the input has a huge impact on how long the procedure will take to complete.
This is called runtime complexity. If an algorithm completes everything, regardless of input size, in one single step, we say it has a runtime complexity "on the order of 1," which is abbreviated O(1). If it takes N steps for an input of size N, then it has a runtime complexity "on the order of N," which is abbreviated O(N). These are not that slow -- but some algorithms are exponentially related to their input, so a large dataset, the kind that machine learning typically uses for image recognition, can easily take hours or days to complete.
So how do machine learning algorithms work? Most are concerned with regression and classification (classification is a special kind of regression). Regression is a statistical concept in which two variables (X and Y) are analyzed to see if Y depends on X. If there is such a relationship, it will resemble a slope. If there is not relationship, the data will be all over the place when represented on a X-by-Y grid or graph. A classification is just a regression that says whether something belongs to one category or another. One such regression, the linear regression, is shown below (Data obtained from The International Disasters Database). The solid line represents the predicted relationship between two observations, but as you can see there are a lot of entries that do not fit that model. This is a good thing -- it allows us to see when there are spurious connections between claims.
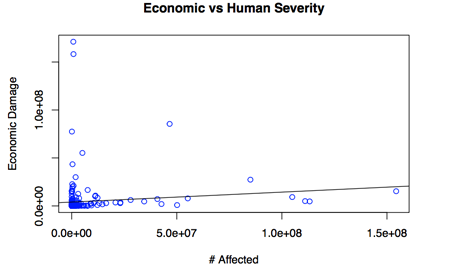
Sadly, most of the hype behind machine learning is misplaced; simple statistical regressions are powerful enough for most use cases, despite not being very exotic. Still, there is a lot left to discover. As computer science is largely an empirical science, these algorithms are worth trying out and seeing what they can do.

This work is licensed under a Creative Commons Attribution 4.0 International License.